Source: MastersInIT.org
If you’re in the market for a career change or still in school and thinking about your future, consider the growing economy around Big Data and Data Science. It’s not just for computer programmers, mathematicians and statisticians — though that’s a strong factor — but also for business strategists, graphic designers and many more. In fact, Big Data will affect many aspects of our lives and Data Science will require new ways of thinking about all the information that we collect.
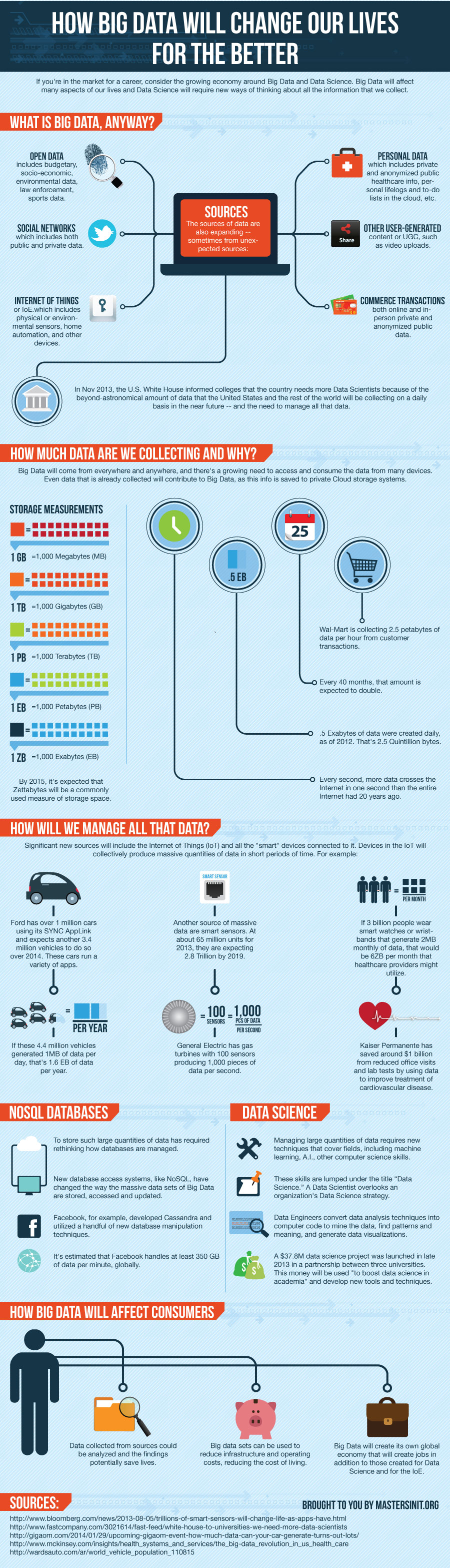
What Is Big Data, Anyway?
If you thought that the amount of data coming from the Mars Rover was a lot, well you ain’t seen nothing yet. The sources of data are also expanding — sometimes from unexpected sources:
- Open Data — budgetary and socio-economic (cities, states/ provinces, countries), environmental data (land, oceans, weather, astronomy), law enforcement, sports data.
- Social networks — which includes both public and private data.
- Internet of Things (IoE) — which includes physical or environmental sensors (sometimes attached to creatures including bees and cows), home automation, and other devices — along with all other devices that are Internet-connected.
- Personal data — which includes private and anonymized public healthcare info, personal lifelogs and to-do lists in the cloud, etc.
- Other user-generated content (UGC), such as video uploads
- Commerce transactions — both online and in-person private and anonymized public data.
This is merely a short list of sources from which the world will collect data.
Are we ready for the massive amounts of data in our future? In Nov 2013, the U.S. White House informed colleges that the country needs more Data Scientists because of the beyond-astronomical amount of data that the United States and the rest of the world will be collecting on a daily basis in the near future — and the need to manage all that data.
How Much Data Are We Collecting and Why?
The data that comprises Big Data will be coming from pretty much everywhere and anywhere, and there’s a growing desire and thus a growing need to access and consume the data from many devices (computers, smartphones, tablets, and more.) Even data that is already collected — such as customer transactions — will contribute to Big Data, as this info is saved to private Cloud storage systems instead of on individual company computer servers.
- Every second, more data crosses the Internet in one second than the entire Internet had 20 years ago.
- 2.5 Exabytes of data were created daily, as of 2012. That’s 2.5 Quintillion bytes = 2.5×10^15 (10 with 15 zeros).
- Every 40 months, that amount is expected to double, so we’re collecting more and more data in short time periods.
- Wal-Mart alone is collecting 2.5 petabytes of data per hour from customer transactions — though not all or any of this is necessarily in Cloud storage.
- To understand what this means, let’s look at some storage measurements:
- 1 Zettabyte (ZB) = 1,000 Exabytes (EB)
- 1 EB = 1,000 Petabytes (PB)
- 1 PB = 1,000 Terabytes (TB)
- 1 TB = 1,000 Gigabytes (GB)
- 1 GB = 1,000 Megabytes (MB)
- By 2015, it’s expected that Zettabytes will be a commonly used measure of storage space. To visualize this, consider: one Terabyte drives started being fairly commonplace in computers by 2013. Kingston’s DataTraveler HyperX Predator 3.0 USB 1.0 TB flash drive has dimensions of 72mm x26.94mm x21mm = 40,733.28 cubic mm (2.83in long x1.06 in width x0.82in deep). Which is probably about the size of an average adult male middle finger, though at least a bit wider.
- Since 1 ZB is 1 billion Terabytes, you need a billion of these drives, which would take up the equivalent of just over 1,412 (1,412.59) cubic feet — or the equivalent volume of a cube measuring about 11.22 feet in each dimension.
- But for Cloud storage, speed is really of the essence. A more industrial strength solution would be a 100TB “drive”, which is actually a bunch of smaller drives combined to worth together, taking up even more space because of drive housings. (While single-drive 100TB drives are in the foreseeable future, but not available at time of writing.)
How Will We Manage All That Data?
In addition to the existing sources of data such as mentioned above, significant new sources will include the Internet of Things (IoT) and all the “smart” devices connected to it — smart watches and bio-medical bracelets, home automation devices, smart sensors, smart cars, and so on. Devices in the IoT will collectively produce massive quantities of data in short periods of time. For example:
- Ford has over 1M cars using its SYNC AppLink and expects another 3.4M vehicles to do so over 2014. These cars can run a variety of apps, including playing Pandora radio stations, paying for parking spots, and managing an ADT home security system.
- If these 4.4M vehicles generated 1MB of data per day (which would be easy to do with sensors, cameras and more) for Ford and technology partners, that’s 1.6 Exabytes of data per year. (Of course, the parking spot sensors are generating their own data, and there are at least 35 cities in the USA with smart parking meters, as of Aug 2013.)
- Imagine if all American passenger vehicles (over 250M registered as of 2010) were “smart vehicles.” Now consider that as of 2010, there were 1.015B registered cars in the world. If at some point in the future, all cars worldwide are smart cars, that’s a whole lot of data generated daily, let alone yearly.
- Another source of massive data in the near future are smart sensors. Estimated at about 65M units for 2013, they are expected number 2.8 Trillion by 2019.
- Some of these sensors are outside on poles near forests, attached to animals or insects, on wind and gas turbines, others in home automation devices and so on. For example, General Electric has gas turbines with 100 sensors producing 1,000 pieces of data per second.
- Then there is healthcare data. If in a few years there were 3B people wearing smart watches or smart wristbands that generate even just a half Megabyte per week or about 2MB per month of health data (pulse, temperature, etc.), that would be 6 ZB per month that healthcare providers might utilize for preventive medicine.
- Of course, there’s already the data that healthcare providers are collecting on their own. Healthcare costs make up 17.6% of the U.S. GDP (as of Apr 2013). This amounts to $2.6 Trillion — which is considered an excess of $600B in terms of benchmarks for a nation’s size and wealth.
- To reduce healthcare costs requires sharing data amongst providers and being able to analyze it nationally instead of in pockets.
- Kaiser Permanente has saved around $1B from reduced office visits and lab tests by using aggregated data to improve treatment of cardiovascular disease.
- Healthcare data is a big market. The U.S. market alone is estimated at $300B (Apr 2013).
- At least 200 new startups formed between 2010 and Apr 2013 that are focused on healthcare applications. 40% of these startups have further focused on health intervention or predictive features.
- The estimated potential yearly savings in healthcare costs is $300B-$450B by applying analysis of big data for predictive and preventive care.
NoSQL Databases
To store such large quantities of data — whether in Cloud storage or not — has in some cases required rethinking how databases are architected and thus managed. Several new database access systems have appeared recent years — collectively referred to as NoSQL — which have changed the way the massive data sets of Big Data are stored, accessed and updated. These included MongoDB, CouchDB, Hadoop, Cassandra and many others.
Facebook, for example, initially developed Cassandra (now an Open Source project managed by Apache) and utilized a handful of new database manipulation techniques because of the way their web servers are structured and located worldwide. It’s estimated that Facebook handles at least 350 GB of data per minute, and that’s from all over the world. When friend networks can span the world, it gets more complicated to store conversation data if web servers are also all over the world. Hence the need for new database systems.
Data Science
In addition to new database systems, to manage such large quantities of data — whether it’s stored in the Cloud or private hard drives — requires new techniques that cover multiple fields, including machine learning, artificial intelligence and other computer science skills, plus modeling, statistics and other mathematical skills, not to mention business strategy in what meaning to look for, and how to use that information.
Collectively, these skills and others are lumped in under the “Data Science” banner. A Data Scientist, in a nutshell, would be someone who overlooks an organization’s Data Science strategy.
Data Engineers, on the other hand, convert data analysis techniques into computer code to mine the data, find patterns and meaning as per the Data Scientist’s directive, as well as generate possibly complex infographics called data visualizations, which are generated through computer code using special code libraries.
The scope of knowledge required for Data Scientists, Data Engineers and other Data Science roles is something of concern. Enough of a concern that maybe we are not ready for managing Big Data that the White House is alerting universities of the need for training “data scientists.”
A $37.8M data science project was launched in late 2013 in a partnership between three universities (New York University, University of California-Berkeley, University of Washington). This money — sourced from two charitable organizations (Gordon and Betty Moore Foundation and Alfred P. Sloan Foundation) — will be used “to boost data science in academia” and develop new tools and techniques, amongst other uses. The project was announced at a meeting sponsored by the White House Office of Science and Technology
How Big Data Will Affect Consumers
Massive data sets will be everywhere. While for the most part they are transparent to the average person, they can potentially benefit everyone in a “smart planet” sense. Data sets that were once collected in isolation could now be aggregated and analyzed on a global basis, potentially leading to more insights.
Besides the convenience aspects of smart cars and home automation, data collected from these and other sources could be analyzed and the findings potentially save lives. Big data sets can also be used to reduce infrastructure and operating costs, thereby potentially reducing the cost of living.
Finally, Big Data will create its own global economy that will create jobs in addition to those created specifically for Data Science and for the Internet of Things.

References
Information for this article was collected from the following pages and web sites:
- https://www.bloomberg.com/news/2013-08-05/trillions-of-smart-sensors-will-change-life-as-apps-have.html
- https://gigaom.com/2014/01/29/upcoming-gigaom-event-how-much-data-can-your-car-generate-turns-out-lots/
- https://www.mckinsey.com/industries/healthcare/our-insights/the-big-data-revolution-in-us-health-care
- https://wardsauto.com/ar/world_vehicle_population_110815