Customer Story: Think Up Consulting Overview
When Think Up Consulting, a brand strategy and change management firm, introduced Microsoft Teams,...
Continue reading

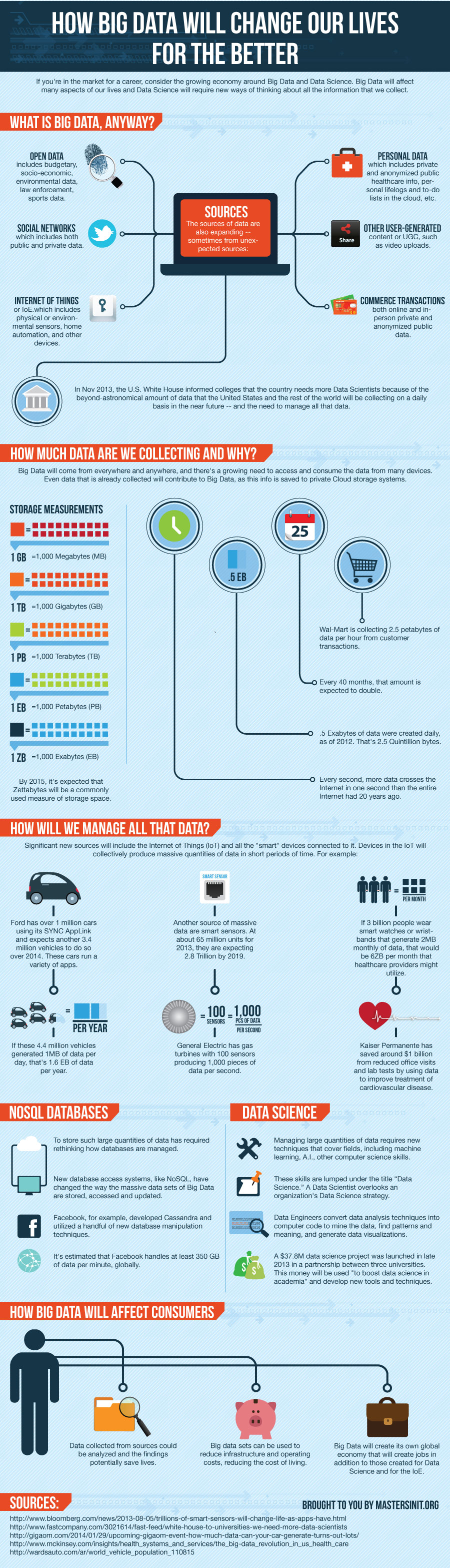
If you’re in the market for a career change or still in school and thinking about your future, consider the growing economy around Big Data and Data Science. It’s not just for computer programmers, mathematicians and statisticians — though that’s a strong factor — but also for business strategists, graphic designers and many more. In fact, Big Data will affect many aspects of our lives and Data Science will require new ways of thinking about all the information that we collect.
If you thought that the amount of data coming from the Mars Rover was a lot, well you ain’t seen nothing yet. The sources of data are also expanding — sometimes from unexpected sources:
This is merely a short list of sources from which the world will collect data.
Are we ready for the massive amounts of data in our future? In Nov 2013, the U.S. White House informed colleges that the country needs more Data Scientists because of the beyond-astronomical amount of data that the United States and the rest of the world will be collecting on a daily basis in the near future — and the need to manage all that data.
The data that comprises Big Data will be coming from pretty much everywhere and anywhere, and there’s a growing desire and thus a growing need to access and consume the data from many devices (computers, smartphones, tablets, and more.) Even data that is already collected — such as customer transactions — will contribute to Big Data, as this info is saved to private Cloud storage systems instead of on individual company computer servers.
In addition to the existing sources of data such as mentioned above, significant new sources will include the Internet of Things (IoT) and all the “smart” devices connected to it — smart watches and bio-medical bracelets, home automation devices, smart sensors, smart cars, and so on. Devices in the IoT will collectively produce massive quantities of data in short periods of time. For example:
To store such large quantities of data — whether in Cloud storage or not — has in some cases required rethinking how databases are architected and thus managed. Several new database access systems have appeared recent years — collectively referred to as NoSQL — which have changed the way the massive data sets of Big Data are stored, accessed and updated. These included MongoDB, CouchDB, Hadoop, Cassandra and many others.
Facebook, for example, initially developed Cassandra (now an Open Source project managed by Apache) and utilized a handful of new database manipulation techniques because of the way their web servers are structured and located worldwide. It’s estimated that Facebook handles at least 350 GB of data per minute, and that’s from all over the world. When friend networks can span the world, it gets more complicated to store conversation data if web servers are also all over the world. Hence the need for new database systems.
In addition to new database systems, to manage such large quantities of data — whether it’s stored in the Cloud or private hard drives — requires new techniques that cover multiple fields, including machine learning, artificial intelligence and other computer science skills, plus modeling, statistics and other mathematical skills, not to mention business strategy in what meaning to look for, and how to use that information.
Collectively, these skills and others are lumped in under the “Data Science” banner. A Data Scientist, in a nutshell, would be someone who overlooks an organization’s Data Science strategy.
Data Engineers, on the other hand, convert data analysis techniques into computer code to mine the data, find patterns and meaning as per the Data Scientist’s directive, as well as generate possibly complex infographics called data visualizations, which are generated through computer code using special code libraries.
The scope of knowledge required for Data Scientists, Data Engineers and other Data Science roles is something of concern. Enough of a concern that maybe we are not ready for managing Big Data that the White House is alerting universities of the need for training “data scientists.”
A $37.8M data science project was launched in late 2013 in a partnership between three universities (New York University, University of California-Berkeley, University of Washington). This money — sourced from two charitable organizations (Gordon and Betty Moore Foundation and Alfred P. Sloan Foundation) — will be used “to boost data science in academia” and develop new tools and techniques, amongst other uses. The project was announced at a meeting sponsored by the White House Office of Science and Technology
Massive data sets will be everywhere. While for the most part they are transparent to the average person, they can potentially benefit everyone in a “smart planet” sense. Data sets that were once collected in isolation could now be aggregated and analyzed on a global basis, potentially leading to more insights.
Besides the convenience aspects of smart cars and home automation, data collected from these and other sources could be analyzed and the findings potentially save lives. Big data sets can also be used to reduce infrastructure and operating costs, thereby potentially reducing the cost of living.
Finally, Big Data will create its own global economy that will create jobs in addition to those created specifically for Data Science and for the Internet of Things.

Information for this article was collected from the following pages and web sites:
Chicago area ERP consultant with over 40 years of experience in Sage 300, Sage Pro, Quickbooks ERP and other systems